





什么是解释变量剔除
解释变量剔除,又称为变量选择或变量剔除,是指在统计分析中,通过一定的方法从一组解释变量中剔除那些对因变量影响不显著或不重要的变量。这种方法在多元线性回归、逻辑回归等统计分析中尤为重要,有助于提高模型的解释能力和预测准确性。
解释变量剔除的原因
在数据分析中,我们往往会收集大量的解释变量,这些变量可能包含一些对因变量影响较小甚至没有影响的变量。剔除这些变量有以下几个原因:
提高模型的解释力:通过剔除不重要的变量,可以使模型更加简洁明了,便于理解。
降低模型的复杂度:过多的解释变量会导致模型过于复杂,增加计算量和解释难度。
提高模型的预测准确性:剔除不重要的变量可以降低模型误差,从而提高预测准确性。
避免多重共线性:多个变量之间存在高度相关时,称为多重共线性。剔除不重要的变量可以减少多重共线性,提高模型的稳定性。
解释变量剔除的方法
目前,常用的解释变量剔除方法有以下几种:
向前选择法(Forward Selection):
从无变量的模型开始,逐步加入对因变量影响显著的变量,直到加入的变量不再增加模型的解释力为止。
向后剔除法(Backward Elimination):
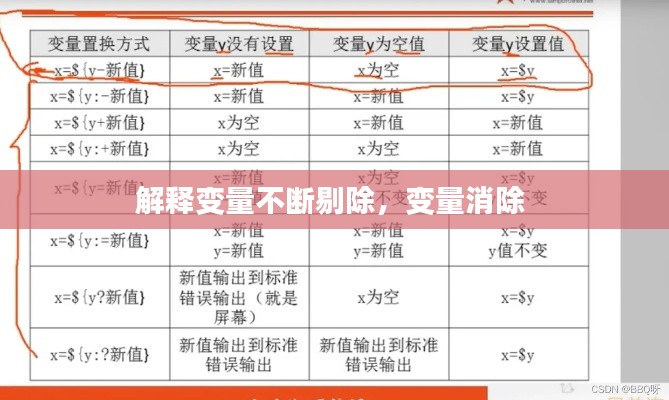
从包含所有变量的模型开始,逐步剔除对因变量影响不显著的变量,直到所有变量对因变量的影响均显著为止。
逐步回归法(Stepwise Regression):
结合向前选择法和向后剔除法,根据变量的显著性水平自动选择和剔除变量。
LASSO回归法:
通过添加一个正则化项来控制模型的复杂度,从而实现变量选择。
实施解释变量剔除的步骤
以下是实施解释变量剔除的一般步骤:
收集数据:收集包含因变量和多个解释变量的数据集。

探索数据:对数据进行初步的探索性分析,了解变量的基本特征。
建立模型:选择合适的统计方法建立初始模型。
计算变量的显著性水平:使用统计方法(如t检验、F检验等)计算每个变量的显著性水平。
剔除不显著的变量:根据变量的显著性水平,剔除那些对因变量影响不显著的变量。
评估模型:对剔除变量后的模型进行评估,如计算模型的决定系数、AIC等指标。
重复步骤4-6:根据评估结果,可能需要进一步剔除变量或添加新的变量。
最终模型:当模型不再改进时,得到最终的解释变量剔除模型。
解释变量剔除的注意事项
在进行解释变量剔除时,需要注意以下几点:
确保数据质量:剔除变量前,应对数据进行清洗和预处理,确保数据质量。
考虑专业背景知识:在剔除变量时,应结合专业背景知识,避免剔除重要的变量。
多种方法结合:可以使用多种方法进行解释变量剔除,并进行比较和验证。
模型的解释能力与预测能力:在剔除变量时,应在解释能力和预测能力之间进行权衡。
结论
解释变量剔除是数据分析中的一项重要步骤,可以帮助我们提高模型的解释能力和预测准确性。在实际操作中,应根据具体问题选择合适的方法,并注意数据质量和专业背景知识的考虑。通过合理剔除不重要的变量,可以使模型更加简洁明了,为决策提供更可靠的依据。
转载请注明来自佛山市艾尚美门窗有限公司,本文标题:《解释变量不断剔除,变量消除 》






 粤ICP备15097574号-6
粤ICP备15097574号-6
还没有评论,来说两句吧...